alan little’s weblog
credit where credit’s due
28th May 2006 permanent link
Credit where credit’s due: I just noticed the bug I reported to Apple a while ago in Safari’s rendering of Sanskrit text is fixed in Safari version 2.0.3
Camino 1.0 and Firefox 1.5 on the other hand, don’t even try to render it, at least not on the Mac.
yegge on programming
10th March 2006 permanent link
Everybody (ok, Bill de HÓra and Tim Bray) is suddenly linking to Steve Yegge’s excellent series of essays on programming, why and how as currently practiced it is grotesquely inadequate for the challenges facing large-scale systems development, and how few people are actually thinking seriously about realistic ways of making it better. Bill thinks he could be “the next Greenspun|Spolsky|Graham”, and could be right, although he seems rather less full of himself than Greenspun or Graham – which is a good thing in itself, but also handicap in rising to fame’n’stardom. [UPDATE: Steve’s currrent blog]
Tour de Babel, the essay Bill links to, is one of the better comparative programming languages essays I’ve ever read, and there’s lots of other good stuff there too about just how primitive the state of our art really still is.
Full disclosure: I make my living managing a team that develops a large suite of software that does [useful things] for [several] million customers of a large telco, at a yearly cost of [somewhat fewer] million euros. (Hey, well under a buck per year per customer. I never thought of it that way before – what excellent value we are!) Anybody who thought that what language the whole lot is written in – mostly Java, as it happens, with odd bits of C++ here and there – is even on my list of Things To Worry About would be sorely mistaken. I’m far more taken up with guessing what marketing might want to do next year, and trying to design this year’s four releases in ways don’t make (a reasonable guess at) next year’s requirements impossibly expensive.
I still enjoy writing code in my spare time, although it’s several years since anybody last gave me money for doing so.
Python is currently the language in which I can sit and type working code without having to worry aobut syntax or reference manuals. My previous experience ranges from the sublime (Smalltalk) to the ridiculous (Cobol), via points in between including C, perl, most major commercial SQL dialects, bits of Visual Basic and a quickly-reached decision that C++ wasn’t going to be worth all the hassle and pain. I’ve never made my living as full time Java developer, but I’ve done enough to know I’m glad I don’t have to. In my moments of python frustration I find ruby the language quite appealing, but I’m put off by its obvious immaturity as a development environment: the laughably slow XML parser, the attitude of Unicode denial. But Steve may have talked me into having another look at it.
i am impressed
14th December 2005 permanent link
James Robertson is clearly very good indeed at his job. I have posted here twice about perhaps-not-wholly-positive experiences with VisualWorks Smalltalk; both times, without any prompting from me, he has found the postings and responded in an entirely constructive and non-critical manner.
The second one was when I found that VisualWorks parsed my large iTunes library file on my Powerbook at about the same speed as python’s not-very-impressive default XML parser, and significantly more slowly than elementtree, which by general consensus is probably the fastest pure python XML tool.
That gave rise to a still-ongoing comment saga on James’s blog, in which several helpful, polite, apparently well-informed Smalltalk enthusiasts are concerned about my disappointing test result and earnestly trying to find out why it might be, without anybody in any way appearing to flame me personally.
What I have learned so far from this:
- My Smalltalk code wasn’t doing anything obviously stupid (I would hope not, since it was based closely on the first example on Cincom’s “How To Do XML With VisualWorks Smalltalk” page). It might be slightly slower than James’s version, but certainly not enough to account for the difference in our test results.
- Other people seem to be able to get XML files of a similar size to mine parsed considerably faster on similar hardware. They are reporting parse times well under a minute against my three minutes – comparable with the pure python version of elementtree, although still nowhere near cElementTree’s 3 to 4 seconds. These are of course not my file – which I have now sent to a couple of people to see how they get on with it. UPDATE: apparently on James’s Mac Mini my file loads and parses in 61.7 seconds. Roughly comparable machines – 1.25 Ghz versus my Powerbook’s 1GHz (and a faster frontside bus), but 256 MB versus my 512MB – so clearly something wrong with my test setup.
- There are two versions of VisualWorks Smalltalk that run on the Mac, a native OS X one and an X11 one. The current native OS X version, which is what I was using, is known to be slow (fix due soon, apparently). James can load and parse my file in 20.6 seconds on his Wondows box.
So it looks like Chris Petrilli was right about Smalltalk performance after all. Even using a notoriously slow version of the Smalltalk VM that is overdue for replacement, it’s still about on a par with the fastest pure python parser.
Far more important than all that from the point of view of James’s job, though, is this: if this is the level of support somebody gets when they are just dabbling with the non-commercial version, what must the paid support be like? Based on this experience I have to say I would be seriously considering VisualWorks Smalltalk if I had free choice of development tools for a significant commercial development(*). (Sadly there is no immediate prospect of me finding myself in that situation). Commercial development tools can’t be an easy sell in these days of ubiquitous high quality open source languages, and VisualWorks isn’t cheap if you’re not an investment bank, but I certainly begin to see how it could be worth it.
(*) Unless the project crucially depended on being able to crunch large XML files very fast, in which case python with cElementTree would still be clearly the right tool for the job.
xml races (4)
13th December 2005 permanent link
James Robertson is surprised that I timed VisualWorks Smalltalk’s XML parser at not much faster than python’s built in one, and finds he can parse a 13 MB xml file in 44.7 seconds on his Mac Mini, which has a little faster cpu but less memory than my Powerbook. Given that James knows what he is doing with Smalltalk, whereas I used to a little bit years ago and have only just started dabbling again, let's assume his code:
content := 'feeds.xml' asFilename contentsOfEntireFile.
parser := XMLParser new.
parser validate: false.
Time millisecondsToRun: [parser parse: content readStream]
… is more efficient than mine (although I did include opening and reading the file in all the other tests too):
XML.XMLParser processDocumentInFilename: "filename"
beforeScanDo: :p | p validate: false.
… then that would put VisualWorks Smalltalk on a par with or a bit faster than the fastest pure python XML parser, but still an order of magnitude slower than python-augmented-with-C.
More.
rss – nobody cares
2nd December 2005 permanent link
Note to authors of blogging software: nobody except you cares about the fact that there are multiple versions of RSS and Atom. When I want to subscribe to something in bloglines, as I did this morning with interesting guy Avi Bryant’s latest project, I do not wish to be asked to choose between five apparently identical feeds using different versions of RSS. Just pick one and use it. Support many different ones if you feel you really must; allow the blog author to pick a different one, or more than one, if you mistakenly think he or she cares; but don’t ask the reader (me) to pick between five identical-looking versions with different meaningless names just to read somebody’s blog.
You could use meaningful names, too: titles_and_summaries_only_dont_bother.xml, full_text_read_this_one.xml – or, in Jim Henley’s case, titles_and_summaries_only_and_months_out_of_date_too.xml.
Thank you.
UPDATE: a case in point
xml races (3)
22nd November 2005 permanent link
XML Races, Part Three. In Parts One and Two, we discovered that for parsing moderately large Apple plist files Fredrik Lundh’s cElementTree is very fast and memory-efficient, whereas python’s standard xml.dom.minidom and Ruby’s REXML are very slow and memory-inefficient.
I was curious to try out another good C implementation – libxml2 with one of its python bindings. I know I have had libxml2 working with python before, but now I have a feeling that may have been on a Windows machine at work, because now when I try to do it on a Mac I find myself firmly back in Open Source Dependency Hell. (No matter how many smooth and positive experiences you have with open source installations, you still always know Open Source Dependency Hell could be lurking behind the next download)
Mac OS X comes with the libxml2 C libraries installed by default, but can Mac OS X’s default python installation see them? It cannot. Can I find anywhere how to cause it to do so? I cannot. I try installing lxml, which is supposed to provide a nice ElementTree-style interface in place of libxml’s default low-level and rather fiddly C-style interface. lxml needs pyrex. I install pyrex. lxml collapses in a heap anyway when I try to compile it.
Oh well. According to Martijn Faassen, libxml might not be that fast with python anyway.
I give up on libxml for the time being, and think instead of Chris Petrilli’s comment that ruby (and python) performance is “not quite in the league of Smalltalk (or Lisp, likely), which have extremely mature VMs with on-the-fly compilation and optimization”. Is Smalltalk then much faster than python or ruby, or comparable with C, for the task of parsing moderately large XML files?
No. Time to load and parse my iTunes library file, an 11mb Apple plist, on a 1 GHz G4 Powerbook with VisualWorks Non-Commercial 7.3.1: about three minutes.
Much faster than REXML, a little faster than python’s default parser. A little slower than a good fast python implementation. Not even vaguely in contention with a good C implementation.
On the subject of unrealistic XML benchmarks, Uche Ogbuji rightly points out that “Nobody reads in a 3MB XML document just to throw all the data away”. True. But in the eight to ten minutes you might otherwise spend waiting for REXML to creep through the document, you can get an awful lot done with your data that you already parsed in four seconds with cElementTree.
UPDATE
James Robertson is surprised, and finds that on his Mac Mini my file loads and parses in 61.7 seconds. Roughly comparable machines – 1.25 Ghz versus my Powerbook’s 1GHz (and a faster frontside bus), but 256 MB versus my 512MB – so clearly something wrong with my test setup. Faster than elementtree, though still much slower than cElementTree. More. More more.
rexml
11th November 2005 permanent link
Just out of curiosity, I decide to continue my XML parser benchmark series with Ruby’s REXML. REXML’s stated design goals are portability (but few things are more portable than ANSI C), standards compliance and a clean API. It’s just as well they don’t include being blazingly fast, because oh dearie me:
Time to load and parse my iTunes library file, an 11mb Apple plist, on a 1 GHz G4 Powerbook with Ruby 1.6:
REXML 3.1.3: eight to ten minutes! Memory used 510mb. At least it garbage collects after it’s finished a lot faster than python does.
The next contender: one of the python libxml bindings. These should be capable of giving cElementTree a run for its money.
(Some people listen to music on the subway; I find the level of background noise too high so I benchmark XML parsers instead. Both beat wasting two hours a day driving a car.)
celementtree
10th November 2005 permanent link
Although I’m interested in Smalltalk, I also have projects I want to work on now in a language I can already use productively. These days that basically means python. Python has its frustrating aspects, but one of the great things about it is that it has really good libraries for lots of things. Fredrik Lundh’s elementtree, for example, has been my XML handler of choice for a while now – it provides a reasonably simple & clean interface whilst also being faster and more efficient than the rudimentary XML tools that come as standard with python.
elementtree is written in pure interpreted python; there’s also cElementTree, a version written in C that Fredrik says is 15-20 times faster and uses 2-5 times less memory. This is interesting: one of the projects I have in mind involves working with some fairly large XML files. So download, uncompress, setup.py install. Change one line in my source code to use cElementTree instead of the python version, and my tests pass first time. Another win for open source installation.
Fredrik’s performance claim appears to be true, even an understatement, for the largest XML file I happen to have lying around just now.
Time to load and parse my iTunes library file, an 11mb Apple plist, on a 1 GHz G4 Powerbook with Python 2.3:
(py)ElementTree 1.2: 70 to 80 seconds, memory used 160mb
cElementTree 1.0.2: 3.3 to 3.5 seconds, memory used 32mb
(Unfair comparison with python’s built-in xml.dom.minidom, which makes no claim to be either fast or compact: 267 seconds to parse the file, plus approximately a week to clean up after itself, memory used 573mb)
UPDATE: in Part Two, we are unimpressed by Ruby’s REXML. In Part Three, we look at VisualWorks Smalltalk, and think about whether the whole exercise has any value.
second impressions
7th November 2005 permanent link
Regular readers (?) might recall that I used to believe one advantage commercial software had over open source was general quality of fit & finish, including slick easy-to-use installers that don’t involve faffing about with version repositories, C compilers and incompatible versions of libraries.
That belief took a large knock a few months ago, when I spent a thoroughly unpleasant and unsuccessful day with Oracle’s byzantine installation rituals before giving up and installing MySQL and PostgreSQL in under an hour (including voluntarily building PostgreSQL from source with a C compiler)
The story continues with my attempts to venture into the wierd world of Smalltalk. A while ago I downloaded Squeak but decided it was just too strange an environment to be worth the effort of learning to use in my severely limited free time. The download and installation were completely painless though, and everything worked first time.
Still hankering after a real programming language, however, I decided to have a look at Cincom’s VisualWorks Smalltalk, which is free for non-commercial use. It has a very good reputation, is the subject of an interesting blog by James Robertson, and Chris Petrilli points out how svelte it is compared to a (roughly) comparable Java/Eclipse setup. Can’t be bad.
Oh yes it can. First of all, you have to register to download the free non-commercial version. This is mildly irritating but understandable for commercial software – perhaps somebody’s bonus (James?) depends on counting the number of “developers proselytised”. Having got past the registration, we are offered a choice of an online installer or downloading a CD image. I look at the installation instructions (pdf) for the CD image; they were last updated in 2002 and refer to the Mac OS X version as a beta. I sincerely hope that is not actually the case, but decide to try the online installer just in case. It (slowly) fires up an installer screen which is clearly a product of the “look out of place everywhere” school of cross-platform GUI development: the fonts and icons it uses aren’t bad, and would probably even look decent on a Windows or Linux box, but they also clearly aren’t Mac-native. I am disappointed to discover that the download is several hundred megabytes despite what Chris Petrilli said, and that Cincom’s ftp server seems to be capable of about 30 kb per second. This is clearly going to be a long job; tracking how long isn’t going to be helped by whoever decided that showing the progress of a several hundred megabyte download in kilobytes, without commas, would be a good idea – so you have to squint at the screen and count digits to even read the numbers.
The progress glacier creeps across the screen, until I forget about it while looking at something else and accidentally put the laptop to sleep. When the installer tries to resume it crashes immediately. I start it up again and go to bed, since by now it is nearly midnight, having already told it at the beginning of the process to skip any existing files it finds. In the morning it has puked this thoroughly slick and professional looking buffer overrun onto my screen:
I will persist with VisualWorks. I am writing this on the subway to work, and have left my desktop Mac gradually downloading the CD image (which I hope really has been updated since 2002). But on quality of installation experience, open source has already won again. Hands down.
UPDATE: kudos to Cincom, though, whose CD installer works just fine, and whose installer guy emailed me within hours of this appearing on the web, saying he has already tried to reproduce the problem and can he have more details? I hadn’t emailed anybody at Cincom yet, partly because I was curious to see whether they would pick up on a blog entry about their product. Test passed, and good luck reproducing and fixing the problem Dave.
languages, languages (2)
7th October 2005 permanent link
Another random thought that occurred to me about languages of a different kind, apropos of nothing in particular apart from still pondering whether to have a look at Rails or some other modern web framework: Java and Javascript.
A few years ago (round about the time I came to Germany, or a little before), Java was being touted as the language of the future for interesting, vibrant, cross platform front end development. Javascript was a trivial toy. Whereas what actually happened was that Java, not surprisingly since IBM adopted it so enthusiastically, became COBOL: the language of choice for important-but-tedious bureaucratic back office projects. Meanwhile Javascript is where Java was supposed to to be: right at the cutting edge of interesting front end development.
UPDATE: Sean McGrath says it was inevitable all along:
Java-based browser applets were doomed from the start because browsers already had built-in virtual machines in the form of Javascript execution environments. It was only a matter of time until the native Javascript environment in browsers became powerful enough for rich application development.
more languages and languages
13th August 2005 permanent link
Ian Bicking has more to say about the complexities of using python and unicode to deal with languages that don’t easily and conveniently map one written character to one sound or one unicode code point, in the form of a pointer to some very useful notes and links from Aaron Lav.
Aaron is mainly interested in Chinese. In Ian’s comments I pointed out that things aren’t completely straightforward in Indian scripts & languages either:
There are all sorts of messy hacks in Unicode.
Take Devanagari for example. Devanagari is the Indian script used to write classical sanskrit, hindi, nepali, marathi and some other languages adding up to the mother tongues of several hundred million people. So quite important to get right really. Devanagari is a kind-of-syllabic alphabet in which consonants are normally are read as including an implicit "a" sound - so "t" is read as "ta". (Unless it's at the end of a word in hindi, I believe). There are supplementary characters to replace the "a" with other vowels or suppress it completely at the end of a word (except in hindi, where it's suppressed automatically anyway at the end a word. I think).
There are also compound consonants, e.g. the "tr" in the word "sutra". These have their own written characters, which are (mostly) recognisable as combined versions of the two root characters. These ligature characters are not conventionally regarded as letters in their own right even though they are written/printed as single characters, and they don't have their own unicode code points. Instead the "tra" in "sutra" is written as three code points: Ux0924 TA, Ux094D VIRAMA to suppress the implicit A in TA, Ux0930 RA.
So how many characters is Ux0924Ux094DUx0930?
It's one on the printed (rendered) page. Linguistically it's normally regarded as two, TA & RA combined. It certainly isn't three, using the VIRAMA to signal a ligature in that way is a Unicode hack not a part of the real script. (Nor is it six, as some idiot who didn't know they were dealing with a utf-8 encoded version might conclude from counting bytes).
(Sorry for the lots of words and no visible examples. It's late at night, I don't know if your comments system would handle unicode examples correctly, and even if it does several browsers - basically all Mozilla variants - don't display devanagari ligatures correctly anyway. I raised this as a bug nearly a year ago, no sign of progress. Presumably all Indian hackers are southerners and don't care if hindi-speaking northerners get to read stuff on the web or not)
UPDATE: having thought a bit more about it, the “length” of the unicode sequence Ux0924Ux094DUx0930 (त्र) depends on what you want to use it for. In different circumstances it can reasonably be said to be any of:
- 1, if you’re interested in allowing space for it on a screen or a printed page
- 2, if you’re interested in how many phonetic units a native speaker would think it contains
- 3, if you’re interested in the internal details of how Unicode chose to implement it
- 6 or 12, if you’re writing low level code to manipulate encoded versions of it
I think (3) is the least common use case, although I suspect it is both what Ian would regard as “correct” and what most unicode libraries would tell you.
on languages and languages
3rd August 2005 permanent link
Not much blogging lately, because I’ve been spending the time I would otherwise have spent writing (a) reading the utterly amazing Shantaram – more on that later, maybe – and (b) looking, again, for a web framework I can use for personal projects.
Regarding the web framework: because this is for something to use in my severely limited spare time, I want something that's quick to learn, and written in a language that’s powerful, elegant and enjoyable to use.
The language criterion immediately rules out C#/.Net and anything using java or perl. That would seem to leave python, ruby, smalltalk or lisp as the ovious language choices. Lisp appears, based on brief googling, to lack decent cross platform open source implementations; it’s a language I'd be interested in looking at one day if I ever have time, but not for now.
So what are the options in python, ruby & smalltalk?
Looking at python first, because I already have some time invested in learning the language and I like it … learnable in limited time immediately strikes Zope off the shortlist. Others? Too many. Although I’m doing this for personal use, if I’m putting my scarce and valuable time into learning something, I would like it to have reasonable-looking prospects of future support & development and maybe long term commercial potential. I briefly experimented with webware, which certainly appears to work, and cherrypy which I thought looked elegant and quite appealing, but neither of them looks very convincing to me in terms of momentum & long term prospects. The latest buzz thang in the python web world is django. Django looks like it could be interesting if the immediate pre-launch buzz actually does translate into longer term momentum, but it has one absolutely crippling flaw that disqualifies it from any serious consideration until they fix it, because …
… my other absolute must criterion, that the boring clumsy restrictive cobols-for-the-21st-century (Java, C#) do seem to get right and the fun, powerful, elegant open source languages by and large don’t, is the ability to work in a sensible way with text in languages other than English. Some of the projects I have in mind involve working with text in Russian and Sanskrit; and one thing I’ve learned from six years working in commercial IT in Germany is that the first thing you do to any prospective vendor’s software is throw a few umlauts in, then laugh and send them away when it immediately collapses in a heap.
The authors of django don’t initially seem to have given much thought to
what every working programmer should know. All that stuff about "plain text = ascii = characters are 8 bits" is not only wrong, it's hopelessly wrong, and if you're still programming that way, you're not much better than a medical doctor who doesn't believe in germs.
… although at least they now realise they have a serious problem with inability to handle non-ASCII data. Ian Bicking, too, has been getting frustrated lately with problems with python’s silly default string encoding and the way setting it to something sensible instead is made deliberately difficult and obscure. Although in my experience, once you have set it to something sensible – utf8 instead of ascii – assuming you have the access rights to do so in the python installation you happen to be using – then text handling in python is reasonably trouble-free.
UPDATE: Martijn Faassen points out, as I did in Ian’s comments, that changing the default encoding in your own python setup, and then coding happily along on the basis that the default encoding is something sensible, will cause your code to break when other people with stupid default encodings try to use it. And Glyph Lefkowitz in an excellent article tells us why we should all get used to the idea of explicitly handling Unicode and abandon the childish assumption that 8-bit byte strings are of any use whatsoever for representing text. He’s right, but that doesn’t mean lots of people will pay attention and do as he says.
One of the things that deterred me from taking a closer look at Ruby on Rails when I first heard about it, is that ruby’s handling of unicode appears to be significantly inferior to python’s. This isn’t just my impression – a search on comp.lang.ruby soon reveals lots of ruby-knowledgeable people saying it too.
With ruby, though, it isn’t just a case of American programmers forgetting to think about the other 95% of the world. It’s far more interesting than that – the Perfect as the enemy of the Good. Ruby’s author, Yukihiro “Matz” Matsumoto, being a very smart Japanese programmer, is probably more aware of and better informed about internationalisation and character set issues than almost anybody. The problem is that being both very well-informed and Japanese, he is acutely aware of Unicode’s faults and failings and possibly shares the commonly held Japanese view of it as a grossly inadequate Eurocentric racist kludge. (From what I understand, the early versions were grossly inadequate for Chinese & Kanji; that was fixed to some extent in later versions but some serious problems, plus probably quite a bit of lingering mistrust caused by the early versions, still remain).
Matz apparently has ideas & plans, possibly even a prototype, of a Grand Unified Solution To Everything in the field of text handling that will be vastly superior to Unicode. Sadly, though, it Isn’t Ready Yet; and until it is, current production versions of ruby are left to struggle on with a half-baked stopgap implementation of utf8. Which is kind of sad for what otherwise looks like a very nice language.
And Smalltalk? I did a Smalltalk project years ago, and I remember the language being very nice to develop in but impossibly slow at runtime on circa-1990 PCs. I assume Moore’s Law has long since fixed that. Python was the first OO language I worked with since then that was sufficiently nice in its own right that I didn’t resent it for the crime of Not Being Smalltallk. Smalltalk these days has a reputedly good cross platform open source implementation in the form of Squeak, and a strong contender for the current title of Most Interesting Web Framework in the form of Seaside. I downloaded them both and they worked first time. But. Squeak is such a wierd self-contained world, I really don’t feel I have the time or the motivation to get into learning my way around it just for the sake of a web framework. Quick googling also makes it far from clear how complete, stable and well-integrated its Unicode support is. So not just now. I appreciate that this may be my loss.
transliterator
22nd July 2005 permanent link
I needed something for a project I’m working on that would let me easily enter romanised Sanskrit text on a normal keyboard (or better still, find romanised Sanskrit text on the internet) and then convert it to proper devanagari Sanskrit text in unicode.
Since I’m acutely aware that, as Phillip Eby puts it: “Python as a community is plagued by massive amounts of wheel-reinvention. The infamous web framework proliferation problem is just the most egregious example”, I did a bit of searching first to see if somebody has already done something similar that I could use/adapt/contribute to. It appears not: I found lots of people telling me how “transliterating” code line-for-line from other programming languages into python produces programs that are un-pythonic, ugly and slow – so don’t do it, folks – but nothing that looked anything like what I wanted.
So I wrote transliterator.py. Version 0.1 is available here for download in case any body else needs something similar. It even has documentation of sorts.
From a command line it works like this:
python transliterator.py text inputFormat outputFormat > outputFile
… assuming you have python installed. Mac and Linux users do. Windows users can get it here. text can be either the actual text you want transliterated, or the name of a file containing it. inputFormat and outputFormat are what you want to transliterate from and to, e.g. “HarvardKyoto”, “Devanagari”. If you don’t specify an output file, the transliterated results will just be shown on the screen.
See the documentation for examples of how to call transliterator from another python program, which allows you to set up your own transliterations and have more control over input and output encodings.
Version 0.1 supports transliteration to and from Sanskrit Devanagari using IAST, ITRANS and Harvard-Kyoto transliterations. Here’s an at-a-glance table of common Sanskrit transliterations. I think it wouldn't be too big a job to adapt it to modern Indian languages. ISO-9 transliteration for Cyrillic (Russian only) is in there too, but I haven’t really made any serious attempt to test that yet. It also supports users adding their own transliterations.
one simple & obvious way
18th July 2005 permanent link
One of the key qualities of python is supposed to be (and is, mostly) its cleanness and elegance. In contrast to perl, where no two programmers are ever supposed to do the same thing in the same way, in python there’s supposed to be “one simple and obvious way to do it”. Let’s look at this, for a couple of different values of “it”.
I discovered when I profiled my current project that it spends nearly half its time in a single function, and that function spends most of its time on a very common and obvious python programming scenario:
you want to look something up in a dictionary, but it might not be there
What’s the one simple and obvious way to do this? There are three. (At least).
Another python programming principle, we are often told, is it is easier to ask forgiveness than permission. So just try it, then worry about what to do if it fails:
try:
value = d[key]
except KeyError:
value = default
That should work nicely as long you’re expecting to usually find what you’re looking for. If your expected hit rate is low (it isn’t in my particular situation, but it could be), then instead of raising lots of exceptions it might be better to look before you leap:
if key in d:
value = d[key]
else:
value = default
But wait. We are also told we should use built in functions from the core python libraries wherever possible, because they are written in C code that is highly optimised and more efficient than anything we are likely to come up with ourselves. And Alex Martelli in Python in a Nutshell points out that python dictionaries have a get method that deals with precisely this situation:
value = d.get(key, default)
That saves us three lines of code (succinct is always good, right?) and should be at least as fast as the other two, if not even somehow magically faster. Er, no, as it turns out:
from time import time
lookups = 10000
hitrates = (1.00, 0.99, 0.9, 0.75, 0.5, 0.1)
for hitrate in hitrates:
d = dict([(i,i) for i in range(1, lookups * hitrate)])
start = time()
for i in lookups:
try:
value = d[i]
except KeyError:
value = 0
print 'Hit rate %f -- time for *try*: %f' % (hitrate, (time() - start))
start = time()
for i in lookups:
if i in d:
value = d[i]
else:
value = 0
print 'Hit rate %f -- time for *if*: %f' % (hitrate, (time() - start))
start = time()
for i in lookups:
value = d.get(i, 0)
print 'Hit rate %f -- time for *get*: %f' % (hitrate, (time() - start))
10,000 dictionary lookups with various hit rates. Times in milliseconds, with python 2.3 running on a 1 GHz Powerbook with OS X 10.3.9:
| Hitrate | try | if | get |
| 100% | 21 | 29 | 30 |
| 99% | 22 | 28 | 30 |
| 90% | 22 | 27 | 29 |
| 75% | 59 | 25 | 28 |
| 50% | 116 | 23 | 28 |
| 10% | 193 | 17 | 26 |
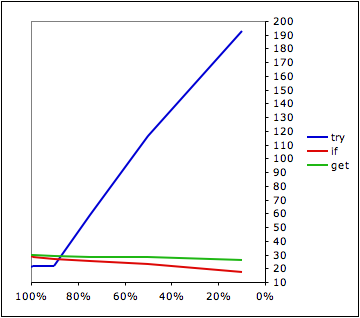
try turns out, not surprisingly, to be the fastest approach if you’re sure what you’re looking for will nearly always be there. This is probably the normal case. Once your hit rate drops off a few percent, though, the cost of raising and handling all those exceptions becomes catastrophic, and then it’s faster to look before you leap. get is always slightly slower than look before you leap. Presumably it’s doing the same thing plus some overhead for the function call. I find it hard to see what it’s there for – why clutter up the standard library with a function that saves three simple & obvious lines of code at the expense of mediocre performance?
What about another common and obvious programming scenario?
you want to develop something that has a web front end
What’s the one simple and obvious way to do this? Zope? Webware? CherryPy? Quixote? Twisted? Subway? (…)
yoga sutras text complete
27th June 2005 permanent link
My Yoga Sutras project now has the full sanskrit text, in Devanagari and romanised using the standard International Alphabet for Sanksrit Transliteration. The bits I’ve checked are correct, but I haven’t proof read the whole thing yet.
Coming soon: transliterator.py, a python module for transliterating between non-roman scripts and common romanised transliteration schemes. Version 0.1 will support devanagari with three common sanskrit transliteration schemes and (sort of) cyrillic. “Soon” means when I’ve finished checking the Yoga Sutras text that it generated and written (some, at least) documentation.
more testing python
23rd June 2005 permanent link
So I don’t fancy using doctest as my main test tool for python; but I do want to know the examples I’m putting in my documentation actually work. But I like py.test now, and I don’t want to have to use two test tools.
That’s ok. I can just call doctest from my py.test script. Like this:
import doctest
import mymodule
def test_doctest():
""" Ensure that the examples in the docstrings work. """
result = doctest.testmod(mymodule)
assert result[0] == 0
It works beautifully. Test tools are not one of the aspects of the python infrastructure that it’s easy to complain about.
testing python
17th June 2005 permanent link
I needed something to do automated testing of a python script for a project I’m working on. Python has several automated unit test tools, but choosing one of them turns out to be far easier than negotiating the python web frameworks labyrinth.
There is a testing module, unittest aka PyUnit, included as part of the standard python library. People don’t generally seem to like it much though – it’s a copy of Java’s JUnit and [therefore?] seems to be verbose and tedious to use. I had a brief look at it a while ago but didn’t get very far.
Next stop: check the blogs of a couple of widely respected python developers to see what they use/like. I recollected both Ian Bicking and Phillip Eby saying favourable thing about something called doctest, and it looks like I recollected correctly. Phillip likes it very much.
I don’t immediately fall in love with the look of the thing, though. Writing a simulation of an interactive python interpreter session inside a docstring seems kinda clunky.
I also notice, googling around, that there’s another thing called py.test that seems to be popular. Ian really likes it. I decide to give that a go.
I really like it too. A little manual path-fiddling required to get it installed and running, but once that’s sorted out it works first time, and it’s really clean and easy to use. A simple naming convention is all it needs: you write a test srcipt called test_whatever.py, containing methods & functions also named test_whatever. If you need it to, apparently it will search directories and directory trees for however many test_whatevers you care to produce; I only have one at the moment. test_whatevers contain normal succinct python code, no wierd or elaborate conventions required, that call the module you want to test and assert what you expect the results to be. py.test runs them and if anything doesn’t behave as expected, reports what actually happened in a very readable format that makes debugging easy. The documentation is pretty good too – a refreshing departure from the open source norm.
Having the test suite written in something as succinct and elegant as normal python seems like a promising way to avoid the biggest automated test problem I’ve had with other projects and other languages: you start off with a nice automated test suite and the best intentions, but maintaining the test cases gradually (or not gradually) becomes more effort than maintaining the actual code. Sooner or later you give up.
Overall impression so far: easily the best automated test tool I’ve used.
Here’s a more detailed and very helpful review by Grig Gheorghiu.
the price of freedom
9th March 2005 permanent link
On the other hand, sometimes installing open source software does require hours of fiddling about with editors and C compilers, but that isn’t always the fault of the people who wrote it.
Now I have MySQL and Postgres working. I don’t have Oracle yet but will soon, one way or another. The next thing I need is python connectors for all these databases. MySQLDB didn’t work on the Mac the last time I tried it, but now I discover it does. That’s nice. Everybody’s favourite Postgresql connector seems to be pyscopg, so I download that; and everybody’s favourite Oracle connector seems to be cx_Oracle so I download that too.
Both psycopg and cx_oOracle, however, need a third party date/time formatting library, Marc André Lemburg’s mxDateTime (because, apparently, the built-in facilities in python weren’t good enough at the time when they were orginally written). I download mxDateTime, which appears to build and install successfully, but then crashes python when I try to import it:
Python 2.3 (#1, Sep 13 2003, 00:49:11) [GCC 3.3 20030304 (Apple Computer, Inc. build 1495)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import mx.DateTime Fatal Python error: Interpreter not initialized (version mismatch?) Abort
I post a cry for help on comp.lang.python, where I have always found people to be super friendly and knowledgeable, and get answers that suggest the problem is a bug in Apple’s standard installation of python 2.3. So now I must upgrade python, following these non-trivial looking instructions. Say bye bye to another afternoon.
Incidentally, Guido says that database drivers having this dependency on a third party library is an undesirable bit of legacy:
I would like the spec to change to require new versions of db API compatible modules to fully support the built-in datetime type, at least when used with Python 2.4 and beyond. The spec current recommends use of a 3rd party date/time type, which was a good idea back when there was no built-in alternative, but which should gradually be phased out now that there is.
Having to fiddle about with too many dependencies (especially when you happen to be trying to develop on a platform where one of your key dependencies doesn’t actually work, for whatever reason) is a major drag on productivity. Which takes us back to the key thing I don’t like about python: it’s no good having a super-productive language if all the time you save on typing code is wasted faffing about with the environment instead of getting more done.
The price of freedom is … eternal fiddling about with incompatible versions of odd little bits of software.
Hopefully this is just start-up cost and once I do finally get a working environment together everything will be lovely.
new project
28th February 2005 permanent link
I am working on a new project. Since I’m between consulting gigs as of this week, I thought it was time to start making a more substantial contribution to open source development than reporting the odd bug and moaning about the state of the python infrastructure.
I’ve been looking at several interesting open source projects in other languages, but I already know and like python, and it would take me a lot longer to get to the point where I could actually do anything useful in ruby, smalltalk or lisp. So python it is, for now.
I wanted something where I could do something useful and substantial in a reasonable amount of time, on a project that already had some momentum. I didn’t want to wander off into the wide blue yonder on my own and build something that would be either hopelessly trivial and obscure, or wildly overambitious and doomed never to get anywhere. What I chose was an Oracle connector for SQLObject.
SQLObject looks like an interesting project that is quite widely respected in the python community. It’s part of two python web frameworks, Webware and Subway. The lead developer, Ian Bicking, seems to be competent and respected and is definitely a nice guy who I’ve already exchanged email with a few times. SQLObject already has working connectors for numerous open source databases and a couple of commercial ones, but nothing for Oracle.
I know about relational databases – I’ve earned my living designing and building them for the last fifteen years, and in particular have spent large chunks of the last five years designing and coding heavy duty financial calculations in Oracle. So I know Oracle quite well from the inside, and I know python reasonably well – so how hard can it be? Hard enough to be interesting, apparently: Ian says:
I wouldn't think it'd be hard, but seeing that everyone starts it (or at least says they have started) but doesn't complete it, maybe there's something mysterious and hard about Oracle support.
I’ve also been emailing with a guy in Russia called Oleg Broytmann who has already been looking at it and says yes, he is finding it hard. He seems to be particularly struggling with special characters – he’s probably using Russian data and so hitting problems early on that an American developing with English-language data wouldn’t find until later. Finding problems earlier rather than later is good. I will of course try to coordinate with him rather than going off on my own.
It’s a great pity, in a sense, that we’re still spending time on this kind of basic infrastructural plumbing when we’re already half a decade into the twenty-first century. The interesting and challenging things about databases should be how do you go about gathering heaps of potentially interesting data to put in them, and how do you then go about extracting actually interesting information from all that potentially interesting data. Not how do you go about the tedious mechanics of shovelling the stuff in and out. But since the tedious mechanics bit doesn’t in fact seem to be quite finished yet, somebody should get on and help finish it. And why not me?
whither python?
11th January 2005 permanent link
Iwan van der Kleyn has opinions similar to mine on python: lovely language, shame about the chaotic/absent infrastructure:
I’m not a language guru nor a framework wizard, but a mere mortal who designs and writes programs for end-users. For that task I need: a better standard ide, an integrated db interface with a proper set of db drivers (!!), a better debugger, a standard widget/windows toolkit, something akin to a standard for web programming, better documentation, a standard lib which is better organized, a formalized set of protocols and patterns for program construction. And an interpreter which is fast enough to avoid using C or Pyrex in most obvious cases.
Of course one valid answer to both Iwan and me would be “it’s all open source, pick where you want to start helping”. To which, however, Paul Rubin (further down in the same discussion) replies
I’m happy to use Python, as it is, for various kinds of noncritical and throwaway tasks. For critical projects I’m looking for tools that work (e.g. Linux, Apache, GCC), not “it’s open source, go fix it”.
Alex Martelli points out that the defined standard language isn’t where such things belong:
what YOU think should happen regarding the infrastructure, and what the people who donate their time to actually make things happen want, may be totally at odds. For example, you appear to keenly want one standard IDE to be blessed and receive all attention, one standard web framework ditto, and so on, and so forth; most core developers, on the other hand, appear to be very modestly inclined to spend their time and energy in that direction, so that only a rather minor fraction of the python-dev effort is channeled that way. Innovative efforts are best kept OUT of the core Python standard, many of us believe, as long as their innovative fervor continues: once something does get into the standard Python library &c, it won’t and shouldn’t develop very fast, nor at all freely, due to the tiranny of backwards compatibility, cross platform support, and the huge increase in maintenance/support efforts that comes when something suddenly becomes much more widespread and widely used than it previously used to be.
Fair enough. I’m all for emergent versus dictated standards. Nobody decreed that Apache should become the world’s standard http server, it became it by being better, and better supported, than the others. But now it’s there and and the rest of us have one less problem to worry about - you want to serve http? Install a current build of Apache and move on to worrying about other, more interesting things. But in web applications, for example, python doesn’t appear to have anything resembling an emergent standard either (unless you want to enter the strange world of Zope). And really, is web application infrastructure such an interesting area for “innovation”? Personally I’d sooner have a mature, supported, widely understood web application framework that I can just use without having to think much about it, and get on with using it to build applications that actually do something interesting.
As Iwan points out elsewhere, the issue with web development in python isn’t that there are no frameworks but that there are too many in various different states of baroque frighteningness (Zope/Plone) or not-quite-finished undocumentedness (the others):
The problem with Python is not that it doesn’t have any web-based frameworks comparable to Rails, the issue is it has too many of them and often much more heavy weight and able than Rails. Zope, Twisted, Webware, Peak are all heavyduty monsters while there are loads (dozens) of solutions implementing parts of the Rail stack much better then Rails does (SQLObject and ZTP are superb examples). But which one to choose? That remains the question.
A couple of related links: A M Kuchling thinks python the language is fine, and the development focus needs to switch to updating and tidying up the standard libraries. Good discussion in the comments section, including the inevitable and not incorrect “well then, pick a standard library, update it and tidy it up!”. And Kevin Dangoor explains why he chose python for a project he’s working on, and some alternatives he considered.
Update: Greg Wilson is “wondering why, ten years on, the Python community still doesn't realize how damaging it is to offer half a dozen half-baked alternatives instead of a single clear answer. Freedom of the press, different systems are best for different things, blah blah blah... I don't buy it any more. I just want the authors of Quixote, Twisted, WebWare, and the rest to sit down, hammer out their differences, and come up with something that's as technically and socially compelling as RubyOnRails”
lazy blogging
15th December 2004 permanent link
A story that turns out to be primarily about superlative customer support for a piece of open source software, with big thanks to Roberto de Almeida the maintainer of pyTextile.
And what does pyTextile do? It takes me one step further in my quest to have home-grown blogging software that fits my needs & wishes like a glove. At the moment AYAWT does everything I want it to with regard to building nicely (?) formatted pages out of a pile of raw entries, publishing them to my hosting service and to a backup, and notifying technorati and various other people. The most laborious bit now – and therefore the next thing to be Simplified – is wrapping my text up in various required bits of administrative xml before I feed it into the AYAWT xml mill. It’s clearly possible to automate this so that I can just feed it plain text with links.
I had a look at various ways I might do this:
- Laboriously write my own. Nah. I’m not that stupid.
- HTMLTidy. HTMLTidy is intended for cleaning up bad html markup, such as what most Microsoft tools produce. It isn’t designed for converting flat text files to html. But in fact, I discovered that if you feed it a flat text file it does a pretty good job. It has just one fatal flaw: it doesn’t convert a blank line to a paragraph break, so everything ends up in one paragraph. I did a fair amount of option fiddling without finding a way of changing this.
- pyTextile. pyTextile is a python port of a well-known perl tool that is expressly designed for producing html from flat text files. It seems to do it rather well, but again when I tested it I found one one fatal flaw: it converts non-ascii characters to numeric codes, ignoring the fact that my files are all nice modern unicode and not bizarre ascii relics of the last century. Furthermore, I would have to wrap this up in an xhtml namespace declaration in order to get it through the rest of my process. I am exceedingly reluctant to even dip a toe into the xml namespace swamp for something that I’m doing on my own time for [some definition of] fun.
- ReStructured Text. ReST is another “simplified” markup language . One look at the how-to page makes it clear that this is not something I’m going to learn in half an hour on the train.
I could mess around putting manual paragraph breaks in before or after using HTMLTidy, but that would be putting one foot on the slippery slope to writing my own. Nah. I’m not that stupid. pyTextile seemed like the least flawed option, particularly when I discovered that the perl version apparently has a way to turn the numeric encoding off.
A bit of searching revealed that pyTextile was originally produced by Mark Pilgrim but is now maintained by Roberto de Almeida. There doesn’t seem to be any kind of support forum or mailing list, so I posted a comment on the relevant entry in Roberto’s development blog; without much hope because the blog entry dated from July and it was now the middle of November. But Roberto replied the next day, saying that switching off the numeric encoding for unicode files was already on his to-do list and he would let me have a pre-release version with it in within a week. Which he did. I did a quick test and it didn’t seem to be working, still getting numeric entities. Didn’t have time to look at it in more detail for a couple of weeks due to the Onrush Of Christmas and Life With A Toddler; but when I did, and sent some sample code and files to Roberto, he replied the same day pointing out what I was doing wrong and providing sample code that does work, like this:
import textile
input = open('input.txt').read()
html = textile.textile(input, input_encoding='utf-8', output_encoding='utf-8')
out = open('output.html', 'w')
out.write('<meta http-equiv="Content-Type" content="text/html;charset=utf-8" >\n\n')
out.write(html)
out.close()
This requires a pre-release version of pyTextile which is up on Roberto’s site at http://dealmeida.net/code/textile-2.0.11pre3.tar.gz. As it’s a pre-release version, don’t be surprised if there are bugs.
(This posting not actually produced using pyTextile, although others will be).
website under construction
10th November 2004 permanent link
No updates lately because I’ve been playing with my weblog software (and still am, so bear with me if things look a bit broken/wierd from time to time). When I first started the blog, I went for a quick’n’dirty build-all-the-pages-every-time approach – which was fine to get something up as fast as possible, and wasn’t a problem when I hadn’t written nearly three hundred entries totalling over a megabyte of text. (Jeez. My PhD thesis was a megabyte Word file; it was much harder work and took a lot longer than a year and half to write). Lately, though, it’s been taking about twenty-thirty seconds to do a build. Twenty-thirty seconds every other day on average doesn’t sound like much; but I do a lot of builds while I’m editing too – I can’t proofread in an XML editor – and it was getting to be a pain.
The new version only builds pages that are affected by changed entries, and for the last week’s worth of entries takes seven seconds. Still too slow. Coming soon: Alan learns to use python’s built-in profiler.
So I’ve been using my blogging time for programming instead of writing entries for the last week or so. For some of that time I didn’t have a working version of the software at all without digging one off a backup disk. Why not? Surely I keep my development code and my live code separate? Not always, for something like this. I have wall to wall backups, and I know if I start messing with my live code, and break it, then I’ll be motivated to press on and fix it. Whereas if a development version doesn’t work, and I don’t have a lot of time available to fix it, I might just drop the whole idea for a few weeks. (No, this is not the way I behave on real projects for clients. It’s just how I choose to spend some of my free time)
In the interests of scientific performance tuning I wanted to change as many uncontrolled variables as possible all at once, so I also switched XML libraries. I had been using the fairly basic, not particularly prorgammer-friendly and not particularly fast ones that come with python. They were adequate for my rudimentary needs but I wanted to try out something a bit more modern and shiny.
Did some playing with libxml2 and quite liked it. Some people find libxml2 a bit too low-level, C-like and unpythonic; I didn’t have a problem with that, and would definitely consider using it for performance-critical production projects. But for doing something in limited time on a hobby project it still seemed like a better idea to look for something a bit higher level. From the reading I did, Fred Lundh’s elementtree looked like the one to try first. It works – installed first time, pretty simple and intuitive to use (although the little utility library I had built around python's minidom was too).
I might still take another look at libxml2 if I decide to do something about seven seconds still being an unsatisfactory build time for my blog – assuming I arrive at some understanding of the python profiler output and assuming XML parsing then turns out to be the actual problem, which it might not be. I didn’t do any benchmarking of my own, but people who have say elementtree is much faster than the standard python xml tools.
devanagari
29th October 2004 permanent link
I did my bit for open source software quality today, by raising bugs against Apple’s Safari browser and Mozilla’s Firefox. Both have – different – serious errors in the way they display Devanagari. Devanagari is the script in which Sanskrit, Hindi and several other Indian languages totalling a few hundred million native speakers are written, so this is not exactly an obscure problem. See here for details and examples, which will look different depending on what browser you’re using.
Internet Explorer 6, I discovered, displays Devanagari correctly. I’m quite surprised to see a case where Microsoft do standards compliance correctly and the open source browsers (Safari is based on an open-source core) get it wrong. Maybe Microsoft have already outsourced their browser development to India? Maybe the world needs more Indian open source developers.
NOTE: I have the highest respect for the programming skills of anybody who would even attempt to write a rendering engine for Devanagari, or any other script that builds compound characters for letter combinations. I wouldn’t like to try it. But it really should be a solved problem by now.
Why did I notice this? Because I started last night on a little project to pull together my notes & thoughts on the Yoga Sutras (योग सुत्र - or not, depending on what browser you’re using) of Patanjali and I thought it would be nice to include the original text. More on this if I ever actually get anywhere with it.
more css nonsense
4th March 2004 permanent link
More from the Alice In Wonderland world of CSS and web standards.
Notice that the previous posting had a numbered list of points, <ol> or “ordered list” in HTML, interrupted with a comment between points three and four. This looks like it should be a perfectly normal and reasonable requirement, and indeed HTML provides an easy way to do it. You just open the second part of the list with an explicit starting number: <ol start="4">. That’s nice. (<ol start="continue"> would be even nicer). However, the page where I found this also says doing it with HTML is deprecated and I should use CSS. I look up how to do it in CSS and I find this:
The deprecated START attribute suggests the starting number for the list and defaults to 1. The value of START must be an integer, but the number may be presented in a different form (for example, as a Roman numeral). While this attribute is deprecated, there is currently no substitute for it in Cascading Style Sheets.
What? I’m supposed to feel guilty of web standards impropriety for doing something perfectly sensible and obvious, in the only way it’s actually possible to do it?
Update: I’m in good company. Tim Bray isn’t impressed with CSS’s ease of use either.
a plea for help
17th February 2004 permanent link
I also noticed while I was away, on my Dad’s PC, that this weblog is illegible in Internet Explorer 5.5 on Windows 98. It seems to display the first half of the text and then lay the second half over the top of it. I assume this is something to do with both IE’s and my general inability to do CSS properly, but I have no idea exactly what the problem might be and I have no easy access to an IE5 / Win 98 test environment to investigate. Any ideas or insights welcome.
photo gallery revamp (2)
29th January 2004 permanent link
On why I hate working with CSS but nevertheless grudgingly accept that it’s on balance not an entirely bad idea.
I’ve just about got the stylesheet for my new-look gallery pages ready after several train journeys and late nights. I really dislike working with CSS: it’s completely unintuitive and getting anything to behave as you want it to requires lots of frustrating trial & error and (if you’re lucky enough not to be on the train at the time) extensive web searching to find out how to do things that should be simple and obvious. At times the temptation to just say stuff it and put everything in html tables, which are conceptually straightforward and work as you expect them to, is overwhelming. But tables are Out (*) so I persisted with CSS because I know it pays off in the long run.
The new look fairly closely copies the look & feel of some of the gallery pages on the Magnum website (always steal from the best!), but I implemented it myself from scratch.
Once you’ve gone through the hours of teeth-grinding frustration and actually have a stylesheet working, it’s worth having. You have a consistent look across all the pages that use the stylesheet without having to do lots of time-consuming and error-prone copying; and you can do fairly major revamps to the look & feel of all the pages just by tweaking the stylesheet. My weblog pages are produced using templates, so the templates are the only html I ever have to edit by hand; but even so, there are several subtly different versions of the template for the main page, for the archives and for individual entries. Even keeping three or four files in synch would be a major pain and would inevitably go wrong sooner or later, so all they contain is a really minimal html skeleton and the real work is mostly done in the stylesheet.
Quite apart from the technical difficulties, I’m also discovering that there’s quite a lot of creative effort involved between having a collection of good pictures, and having a collection of small jpegs with a consistent size and look that I can use as the index to an online gallery.
- I want them all to be the same size and shape (square, probably). The ones I have had so far have been different: I think a gallery index page looks better if they are all the same. What I use as the “small” version of a picture for an index page has also tended to get larger since I started the site four years ago: fewer people are on dialup connections these days, and I’ve become more concerned about visual impact than download times.
- This means I will have to revisit most of the pictures I have had in the gallery and at least re-crop and re-size them – with the attendant danger that I’ll end up completely re-editing them when I look at them again and realise I can do a much better job with them now than I could then.
- I thought about keeping the actual jpeg files I already have, and just using the height and width in my img tags to get them all to display the same size, if only as a stopgap. But I’m not going to. I don’t want to waste my readers’ bandwidth (or mine) sending out larger files than I need to; and more importantly, do I trust the image resizing algorithms in Photoshop, or the ones in some random web browser? You only have to look at the browser itself to see how visually talented browser programmers generally are(n’t).
- I might have a landscape picture that looks stunning as an A3 print or a double-page spread in a magazine, and even ok as a reasonable size web image; but it’s going to look like nothing if I just squeeze the whole thing down to a 200x200 thumbnail. It might take several minutes of looking and trial-and-error in photoshop to find some part of it that actually works as a small square crop, assuming it’s possible at all.
- I’m not sure about mixing black & white and colour pictures on the same page. But if I don’t, then I’ll want to find some way to make it really obvious on the colour page that there’s also a black& white page and vice versa
(*) I make reasonable efforts to build this weblog as standards-compliant xhtml. The main page isn’t valid at the moment, however, because I have an unescaped ampersand – “&” instead of “&” – in a link somewhere, and in xhtml that is a Sin. I’ve checked the text file that the original link is in, and everything is fine there; so somewhere along my production line there is a bug that un-escapes it. Mea culpa. But I really don’t have the time – and frankly don’t care enough – to bother fixing it. The offending link will automatically drop off the bottom of the main page in a month anyway and then I’ll be valid again. For what it’s worth. See also this entertaining rant from Mark Pilgrim on just how little it is, in fact, worth.
spammers for free speech
17th January 2004 permanent link
I am working on one or two big pieces about Art-With-A-Capital-A, partly inspired by recent comments by Brian Micklethwait about the influence of photography on painting. Meanwhile, trawling my “weblog ideas” folder for something else worth mentioning, I came across this that I noticed in November:
Spammers for free speech: a thought-provoking piece by Ian Bicking. Statistical filtering techniques are becoming increasingly effective these days, with their development mainly driven by the war on spam. (Even Apple’s mail filter, which used to be utterly ineffective, actually started working in OS X 10.3 to my great delight). If spammers discovered a surefire way of getting past bayesian filters it would render email obsolete overnight.
However, every sword is double-edged(*). Filtering techniques, as well as fighting the good fight against spam, could be misused for malign purposes such as internet censorship by governments. If a way of defeating spam filters also blew a huge hole in the “Great Firewall of China” then it would not be entirely a bad thing.
(*) Metaphorically. I have seen plenty of single-edged Japanese swords in museums, thank you.
technology winners and losers
5th January 2004 permanent link
Tim Bray has a couple of interesting pieces on technologies that have been influential Winners and Losers in computing over the last couple of decades. I agree with all of Tim’s choices, and have thought of a few more possibilities:
Ethernet and TCP/IP (Winners) versus Token Ring and X.400 (Losers) in networking.
USB (Winner) is unglamorous, but has been hugely influential as the first technology that actually made connecting accessory devices up to PCs painless and reliable. This despite being clearly technically inferior to Firewire – which I wouldn’t list as a Loser, it’s widely used and I think unlikely to go away for quite a while, but it is and will remain less ubiquitous than USB.
I’m not too sure about listing perl and python – both as candidate Winners, obviously. Tim mentions open source as one of his Winners. I think perl and python may be important enough to justify not just lumping them under that heading. Somebody (I forget who, it may even have been Tim) cited them recently as the most important examples of open source being capable of producing major innovation, and they are prime exemplars of worse is better and less is more in design philosophy (no prizes for guessing which I’m referring to as which). However, one could argue that C (cited as a winner by Tim) is an earlier and more influential example of both philosophies; and that Lisp is pretty significant prior art in terms of a very powerful high level language. And although it’s undeniably nice, it’s by no means clear to me that python has the infrastructure to be a major long term influence.
(I remember reading books about Object-Oriented Databases, Tim’s first Loser, around 1990 and thinking “wow, this stuff is clearly better than relational”. Which turned out not to be the case.)
more thoughts on python
11th December 2003 permanent link
David Pinn asked me what I now think of python.
I’ve been using python part time for a few months now, and I’ve already written enthusiastically about it several times. It’s a really nice language. I find some parts of the class system a bit obscure and wacky, but in general I love it. It’s concise, elegant, powerful, and treats the programmer as an adult. It assumes you know what you’re doing and can generally be counted on to behave decently. Very unlike, say, perl – concise and powerful, undeniably, but “elegant” only for very specific values of elegant – or java, with its paranoid nanny of a compiler that assumes you are an imbecile.
If a piece of design tells you about the designer as a person – and I think it does – then Guido van Rossum must be a seriously nice guy.
However. A serious modern development environment needs more than a nice language. It needs solid, standard frameworks for web applications, GUI development, interacting with common databases and crunching XML. The standard GUI doesn’t even have to be any good – just look at Java. Python has (nearly) one of the above.
The XML tools, from what I’ve seen, are excellent. So far my weblog tool gets by with the standard libraries, and if I wanted to get more sophisiticated it’s not at all clear to me whether I should be using 4suite or libxml2. But either way, in this case there’s no doubt that I can get something that is powerful and reasonably standard and supported. From what I’ve seen of third party python libraries so far, though, I suspect installation of either of them on OS X might not be completely plug’n’play.
For GUIs, python has nothing that comes as standard. wxPython seems to be the current preferred cross platform library, but the only wxPython GUI I’ve actually seen – the Chandler alpha release – looks dreadful. I hope it’s just because they haven’t got round to addressing look & feel yet – but if Chandler is supposed to be some wonderful poster child for open source, cross platform end user apps with a professional standard of fit & finish, perhaps they should. PyObjC sounds like it might be the way to go for Mac GUI development, but it’s not cross platform.
Web applications. Complete shambles. There’s no standard way of even hooking up to a web server, never mind application frameworks. If I want something better than CGI, what’s the official (sanctioned-by-consensus would also suffice) equivalent to mod_perl or mod_php? Is it mod_python? mod_snake? Neither? How am I supposed to know? And if I want to go more towards frameworks, there’s zope which has a reputation for being very powerful but a bit of a wierd & wonderful self-contained world, webware which is a nice prototype, and seemingly dozens of other ideas floating around in various states of half-finishedness. This is a bad mess. What to do about it is a constantly recurring topic on comp.lang.python – more of my thoughts on the matter in this discussion.
For databases – well, I haven’t got round to trying to fix the mysql installation for OS X. But to not work with the most popular open source database on the most popular desktop unix: really not good.
Compare and contrast Java. Java is the COBOL of the 21st century. It’s nowhere near as nice a language as python, but it’s not all that bad. The world (especially Bangalore) is full of competent Java programers. It has stable, standard libraries and frameworks for doing just about anything you could possibly imagine (even GUIs if you don’t mind them being ugly and slow). It’s no wonder it has solidly established itself as the standard language for corporate back office development.
Whereas python is a lot of fun, but I have a hard time seeing how I could seriously recommend it for anything except fairly small standalone projects at the moment. Which is a shame.
rss alternate - broken?
12th November 2003 permanent link
Hmm. I thought adding RSS auto-discovery tags to my weblog pages would be a quick & easy way to increase my web-standards-coolness quotient. Er, no, as it turns out.
RSS auto-discovery tags look like this:
<link rel="alternate" type="application/rss+xml" title="alan little’s weblog" href="http://www.alanlittle.org/weblog/index.rss" />
… and they tell news aggregators looking at a normal web page where they can find a version of it where they can track updates automatically.
Problem is, this assumes that the content of a web page can/should only be found in one RSS feed. What if I want to offer feeds in several different formats? What if I want to have subject-specific feeds, and my weblog entries have their own pages and can be in more than one subject category? What if I want to allow readers to define their own custom feeds, as I know a couple of people are doing?
I’m not, in fact, doing any of these things at the moment or planning to in the immediate future — which means my declared allegiance to the software engineering principles of Do The Simplest Thing That Can Possibly Work and Never Add Functionality Early should mean that I just shut up and add a link to the one RSS feed that I actually have. Which I will, but I’m still uncomfortable about implementing something with an object model I know is Wrong.
press release
6th October 2003 permanent link
Alan’s weblog now has an RSS feed – another triumph for the power of python and Alan’s super-sophisticated five line templating engine.
The feed looks ok in NetNewsWire Lite and has survived a pass through feedvalidator.org. If anybody has any problems with it despite this rigorous quality control process, I’d be grateful to hear about them.
And more joy of python: converting all relative links (including images) to absolute links so as to remove a potential source of confusion for newsreaders. Four lines, ten minutes:
attribsToConvert = {'a':'href', 'img':'src'}
for k in attribsToConvert.keys() :
for e in xmlText.getElementsByTagName(k) :
e.setAttribute(attribsToConvert[k], \
urlparse.urljoin(baseURL, \
e.getAttribute(attribsToConvert[k])))
# urljoin does nothing if the url is already absolute
more beauty of python
3rd October 2003 permanent link
Time to add archiving to AYAWT, two hours: one hour in the evening after putting the baby to bed to sketch out the basic concept and object model; one hour in the morning before work to test & debug.
It’s amazing how good programming languages & tools are getting these days. I can have a family, a day job, a life - and still, in the odd half hours (or even occasionally whole hours) that I happen to find lying around, have fun producing a non-trivial working system that makes my life easier. This just wasn’t possible a few years ago - I remember ten years ago setting out to do some similar personal projects in Microsoft C++ version 1 (no Linux or Java then, and I hadn’t heard of perl or python), and there was just so much hard work and bullshit to wade through before you could actually get close to having anything useful, I gave up. The things I wanted to do weren’t worth sacrificing entire evenings and weekends to something that wasn’t fun. Now, with python running on a unix-powered iBook, it doesn’t have to take whole evenings and weekends and it is fun. Part of the fun is that the language is clean and elegant, part is the “wow, I thought that was going to be a big job, and now two hours later here it is working” factor.
It’s not just having a nice language to program in - it’s that plus free software and the web. Not sure how to do something? Google. Google doesn’t know? There’s always usenet. Standard library doesn’t do what you want? Download a better one. The language is a bonus, but I’m sure if I was a high-powered perl hacker I could churn out this stuff at about the same rate as I’m churning it out in python. The difference being, it would have taken me a lot more than a few weeks of part time dabbling to be as fluent in perl as I am in python. Java is probably fairly similar to python in terms of the ease of learning the actual language; its libraries are at least as good as the ones for python and perl, and better documented. But if I only have half an hour to get something useful done, I don’t want to waste half my time fighting with a brain-dead compiler that wants to to be told about every exception I might throw, forgets what my objects are every time I put them in a list, (etc. etc. etc. - refrains from launching into long rant about the amount of irritating time-wasting nonsense that is in java even though it’s basically a fairly nice language). So actually, on reflection, maybe having a nice language to program in is as important as those other things.
the beauty of python
1st October 2003 permanent link
After only a few weeks of developing in python in my limited spare time, I'm discovering that it's remarkably easy to do things that look complicated and daunting at first sight. I've already mentioned the state of the art software engineering principles on which ayawt is based, two of which are:
- Do The Simplest Thing That Could Possibly Work
- For any given text-processing problem, XSLT is unlikely to be The Simplest Thing That Could Possibly Work
Item (2) notwithstanding, it would be difficult to build a web page generator without some kind of templating mechanism. Fortunately, python comes with one built in in the form of string substitutions. In their simplest form they look like this:
'the %s is %s' % ('grass', 'green')
What this says is "replace the %s bits in the string with the values from the supplied list, in the order in which you find them", resulting in 'the grass is green'. Then there is a slightly more sophisticated version where the tokens to be replaced have names, and are looked up in a dictionary (hash table) of names and values.
'%(colour)s are the %(vegetable)ss' %
{'vegetable':'carrot', 'colour':'orange'}
... produces 'orange are the carrots'. This was what I decided was The Simplest Thing That Could Possibly Work for my templating mechanism.
The templates look something like this:
<!-- xhtml headers, link to stylesheet etc. ... --> <body> <h1>%(weblogTitle)s</h1> <h2>%(entryTitle)s</h2> %(entryText)s %(entryPermalink)s <!-- etc etc ... -->
And I was fine as long as I made sure I had the same tokens in all my templates, (which I did by starting off with the same template for every page) but having to have the same tokens in all my templates clearly wasn't going to be a particularly flexible long term solution. What I needed for more flexibility was something that would parse all the token names out of the template, and dynamically build the dictionary of token values by mapping the names to properties of my page class. Not exactly a major problem conceptually, but in any language I've ever used before it would be rather more than I would expect to be able to knock out in half an hour on the train. Not in python, though, where turns out to be as easy as:
import re # standard python regular expression library
# regexp to extract tags from the template
rex = re.compile(r'%\((?P<value>.+?)\)')
class page (object) :
# ... initialisation code omitted
def build (self) :
tokenvalues = {} # empty dict
for token in rex.findall(self.template) :
attr = self.__getattribute__(token)
tokenvalues[token] = (callable(attr) and attr()) or attr
outfile = open(self.url, 'w')
outfile.write(self.template % tokenvalues)
close(outfile)
Some metrics:
- Lines of code that actually do the work: five (easily reducible to one - see below)
- Time to get the regular expression for extracting the tags from the template right: about half an hour
- Time to write & test the rest of the code: about 10 minutes
- Worked when applied to the test version of alanlittle.org: first time
There are existing python templating libraries, webware psp and cheetah being two of the ones I've heard of. I'm pretty confident that it would have taken me more than 40 minutes to install, test and learn one of them and rewrite my templates. I'm absolutely certain it would take me more than 40 minutes to learn XSLT. And I think my approach is fairly flexible - in principle I could switch to a "standard" weblog templating language like blogger or Moveable Type just by changing my regular expression and adding a few methods (assuming I wanted not to be able to do all the cool better-than-blogger-or-Moveable-Type things that AYAWT will (?) be capable of one day).
Even for a novice python programmer like me, there are obvious ways to boil this down still further. Using python properties instead of attributes & methods would avoid the inelegant (callable(attr) and attr()) or attr bit without having to write heaps of ugly java-style get methods. Assuming python has a function for constructing dictionaries out of lists of value pairs (which I expect it probably does, and if it doesn't it would be a five minute job to write one) you could actually write the whole thing as a one-liner (note: pseudocode):
open(self.url, 'write').write(self.template % \
dict([(tag, self.__getattribute__(tag)) \
for tag in re.compile(r'%\((?P<value>.+?)\)'). \
findall(self.template)]))
But would the one-liner actually be better, other than for deriving a smug sense of one's own cleverness bordering on that of Lisp programmers? Elegance and succinctness are in principle Good Things, and I don't have any problem with the legibility of the shorter version, but I can think of a number of practical arguments in favour of the slightly more verbose approach. Python's significant whitespace is generally nice once you get over the initial shock, but does get in the way of making elaborate one-liners legible - line continuation backslashes are ugly and a pain to type, and cause irritating syntax errors when you forget one. Complex nested expressions are harder to debug because you can't easily get at the intermediate stages. Compiling the regular expression in advance is probably slightly faster (minor benefit) and keeps the nasty regexp syntax as far away as possible from civilized code (major benefit). I don't know how in the one-liner to get and close the implicit file handle that we're writing to - it would be nice if python automagically closed it when it goes out of scope (and perhaps it does?).
But, leaving aside stylistic questions of slightly verbose versus as-terse-as-possible, python is really very nice.
your blog's got mail
25th September 2003 permanent link
One of the things coming in a future version of AYAWT will be weblogging by mail. I think I would sometimes find email more more convenient than a web interface; what I don't want, obviously, is things being published on my weblog that aren't actually by me. (I'm sure there are hordes of people out there just waiting to pass their deluded opinions off as mine).
So, how to combine convenience with a reasonable level of security? Whitelisting the addresses that are allowed to post by mail will clearly help a bit, but is far from adequate because it's too easy to forge mail headers. I think I'm probably going to go for whitelist plus challenge-and-response - that way, the system is as secure as access to my mail accounts, which is good enough.
The process would look like this:
- I mail a weblog entry to the address that the AYAWT is watching (e.g. weblog [at] alanlittle {dot} org)
- AYAWT checks that the mail appears to be from an approved (whitelisted) address
- if so, it parses the message into my standard weblog entry format (including automatically extracting any external links for use as sidebar links, if a configuration settng tells it do do so)
- it adds some kind of not-too-easy-to-forge magic number - I'm thinking something like an MD5 hash of part but not all of the message
- then it mails the formatted entry, with magic number, out to the weblog editor email address (me)
- I get the message, possibly edit it, and send it back with something to indicate approval, still with the magic number attached
- AYAWT receives the approval message, checks the magic number, and if it's ok publishes the entry
No security-through-obscurity here. No real security at all, I'm sure anybody who knows anything about these things would say, but I think it will do for my little obscure weblog.
I notice Dave Winer is touting mail-to-weblog as a big deal new feature in Manila. It looks easy enough to me - probably because I haven't actually tried to build it yet. Their security mechanism - whitelist plus a password embedded in the subject line - looks easier to use than mine but even less secure.
In related weblog tool development news, I notice that Kimbro Staken, who emailed me in response to one one of my earlier comments about python on OS X, is also building a python-xml content management system and is further on with his than I am with mine. Russell Beattie has also been thinking out loud about something similar in Java. Everybody's doing it. Russ and Kimbro both seem to be focused on Big Thoughts about Architecture; whereas my one hour a day (max) of available development time forces me to be adopt the latest hot software engineering practices. I don't have time to do anything except The Simplest Thing That Could Possibly Work; I definitely Never Add Functionality Early. You won't find any Premature Optimization in my code either, thank you very much.
AYAWT 0.1
10th September 2003 permanent link
Alan’s Weblog is now brought to you by version 0.1 of Alan’s Yet Another Weblog Tool (which needs a better name). It’s written in python using xml files as the data store (haven’t had the time or mental energy to return to the struggle to get the python-mysql connector to work on the Mac). I’m enjoying python, and I’m impressed that I’ve been able to produce a non-trivial working application in the course of three weeks’ train journeys to & from work - say about ten to fifteen hours work in total - using a language I had previously only played with for a few hours. (This also explains the long writing hiatus - I can spend my time on the train writing or coding, but not both.) If I’d used java I don’t think I would even had time to type the code in this amount of time, much less get it to compile and actually work.
There are still one or two quirks - the odd non-English character might come out looking a bit, well, odd. This is due to the standard python xml libraries choking on perfectly valid html-encoded characters even when clearly told that they are looking at an xhtml document. Haven’t had time to decide what to do about that yet.
UPDATE 4th October: it turned out that ’what to do about that’ was, change my default character set in BBEdit from ’Mac-Roman’ (whatever kind of quaint retro-look relic of the 20th century that might be) to ’utf-8’. Which was nice and easy - I thought I was going to have to write some kind of Tim Bray-style utf-to-html-and-back conversion routine.
It also occured to me that, for what version 0.1 does - basically, take bits of xml and stitch various permutations of them together to make xhtml pages - I hardly needed to use a programming language at all. I could have achieved the same effect with some combination of something like ant or make with a command-line xslt processor. (Or even ant or make without an xslt processor, just supposing I didn’t care about alienating readers who don’t have xslt-capable browsers). Of course, that approach might lack a bit in the scaleability department, wouldn’t be expandable to do all the marvellous and clever things my python program will (might) be expanded to do in the future, and would have involved spending my precious time learning xslt (not fun) instead of python (fun).
installation day
8th August 2003 permanent link
Thursday was Day One of a new consulting gig - actually not so new, back with a client I’ve done work for a couple of times before. Go and visit the old team; learn interesting & useful German phrases such as der Täter kehrt zum Tatort zurück (“the criminal returns to the scene of the crime”). Nice to know one’s work has been appreciated in one’s absence. Apart from this absolutely job-relevant cross-team liaison activity, it’s Software Installation Day. Hurrah. It’s a Windows shop. I do so enjoy watching Windows reboot. (Good job I have the new phone to play with). At least they’re on Windows 2000 now - last time I was here they were still using NT.
So, what are the basics that we need for a minimally civilised existence in Windowsland?
- Mozilla Firebird. Check
- ActiveState perl. Check
- Oracle client. Check
- Apache. Check
- UltraEdit. Oops. Since I ditched my own Windows box in favour of a Mac my UltraEdit license has expired. Will have to get a new one - Mr. Mead deserves to get paid for his excellent work.
- Java SDK. Oops
- ... Java SDK refuses to install without having local admin rights to set JAVA_HOME. This company has a policy of not giving anybody local admin rights without a long & tedious struggle with bureaucracy. Reasonable enough for everyday users I suppose; but as a developer how on earth do they think you’re supposed to be able to do your job without admin rights on your own PC? Try the old favourite NT logon screen admin rights hack (probably the easiest root hack ever to work on any OS, go Microsoft) - doesn’t work on 2000. Mentally prepare for long & tedious struggle with bureaucracy.
- TOAD. Not free & not cheap, so also requires long & tedious struggle with bureaucracy in the form of a purchase order. Get manager to place purchase order. Meanwhile find former colleague who has working version on a CD - strictly an interim measure, the people at Quest Software also deserve to get paid for their efforts.
weblog design (1) - sidebar links
4th August 2003 permanent link
Part One of a series of design notes which will grow into a functional spec for Alan’s Personal Weblogging Tool. (Which needs a better name). I will be building the functional spec in parallel with the code. Yay. Evolutionary Software Design.
Sidebar links. This is an area where I want to try to do fancy stuff that I don’t think any if the available weblogging tools do.
- Auto-generate sidebar links for each item from the things I’ve linked to in the item text.
- If an item is on more than one page, which many items quite easily could be - a “main” weblog page, a dedicated page for the item, one or more category pages, a chronological archive page - then I might want different sidebar links depending on what page the item is being shown on - just one of two key ones for multi-item pages, all of them if the item has a page of its own.
- Auto-generate won’t be easy because I might not want the sidebar URLs and link text to be exactly as in the article. For example if I’ve linked to an item in somebody else’s weblog, I would probably want the sidebar link to be to their main weblog page not to the individual item. Having a resaonable stab at truncating URLs and checking the shortened version might be just about within my coding abilities - but I might also not want the same link text, and generating different link text automatically is definitely beyond my coding ability.
- I could, of course, check if I’ve linked to the same site before and default to the same URL and sidebar link text I used last time.
- Pages for individual items should also (by default, switchable) inherit sidebar links from any categories they are assigned to.
- Category-level sidebar links can be defined manually, or by automatically “promoting” to category level any sidebar links that are used in more than a certain number or percentage of posts in the category.
i don't get rss
3rd August 2003 permanent link
I don't get RSS.
This may mean I'm terminally technically un-hip, but I've tried out NetNewsWire Lite a couple of times and I just don't see what it does for me that a set of bookmarked tabs in Mozilla or Safari doesn't. Let's see: a set of bookmarked tabs:
- can also include websites that don't have RSS feeds (*)
- shows me the full text of all the items I want to read in one window, whereas lots of RSS feeds only have summaries, and then NNW opens everything I click on in new browser windows and eats up my precious desktop space - the only scarce commodity on most computers these days.
A set of bookmarked tabs can't:
- update itself automatically when one of the sites I'm interested in reading posts new material
... but that's a feature not a bug. I already spend far too much time catching up on news in the morning before I start doing any actual work, I don't want that spilling over into the rest of my day too.
There are a couple of important things that neither a browser nor an RSS reader can do for me at the moment:
- neither a browser nor an RSS reader can deal with synchronising my subscriptions, bookmarks or whatever across multiple machines. I regularly work on my desktop, my laptop - both Macs - and a variety of Windows machines at client sites. I want all the machines I use on a regular basis to know what I'm currently interested in. Dave Winer has a project to deal with this for RSS feeds, which I remember reading about a while ago but can't find the link for just now - but what about all the websites I want to read that don't have RSS feeds? I have a several semi-private blogger pages that I use as notebooks for various subjects, but I don't actually use them as much as I would like because writing a post in blogger is significantly more work than saving a bookmark in a browser. I want a two-or-three-click solution that maintains a master links page on a server and can synch bookmarks with Safari, Mozilla or Internet Explorer. (So I guess I'd better get on with writing one then).
- neither a browser nor an RSS reader can show me discussions that are happening across a number of sites as a coherent thread. Movable Type's trackback seems like an idea that could have some potential for dealing with this, but has some major limitations. Technorati looks interesing in this realm too - although again only for sites with RSS feeds. What I'm thinking of is some sort of linking syntax that says Post B "comments on" or "replies to" Post A and a viewer that can show me Post A and Post B in the same windows regardless of what website they originally come from. Which of course starts to drift dangerously close to real hypertext as conceived by the likes of Vannevar Bush, Ted Nelson and even Tim Berners-Lee.
(*) Examples of indispensable tech news and commentary sites that don't have RSS feeds - Clay Shirky, David Isenberg, Jerry Pournelle. Plus of course Lileks and the What's New page on Luminous Landscape, my favourite photography site.
This doesn't mean I won't be providing an RSS feed at some point when my weblog generating tool becomes more sophisticated than just me and BBEdit - I don't get it but clearly lots of people do.
python and java (and perl)
26th July 2003 permanent link
Russell Beattie has written a couple of articles recently on python from a java programmer's perspective. I haven't put as much time and effort into trying out python as Russell has - in fact, I gave up and went back to java pretty quickly, because that way I could be productive instead of spending hours and days banging my head against the kind of frustrations Russell has written about.
My previous consulting gig finished at the end of June, and with all the time I suddenly had available (in an apartment with a six week old baby - ha!) I decided to get moving with a couple of programming projects I've wanted to do for a while - an analyser for my web server logs, and a weblog tool. (Yes, I know there are dozens of both readily available, many of which are free and open source, but that's not the point ...). I've been thinking for some time that it would be nice to learn python, and one or both of these seemed like an ideal easy-but-interesting starter project. On the other hand, I hadn't used java for a while and from a looking-for-employment point of view I thought it might not be a bad idea to brush that up a bit. Nevertheless, I decided to start with python - which I had already played with a bit using Mark Pilgrim's excellent Dive Into Python - on the basis that it's a nicer language. I still think it is, but read on ...
First I needed to get my development environment set up with various tools that I knew I was going to need. I'm used to perl, where tools to help with anything you could possibly want to do are available on cpan and you just download them - or, if you're on Windows, you just fire up activestate's excellent module installer and it does everything for you. Or java, where most of what you want is in the standard libaries and if you do need something third party, such as the excellent JFreeChart, you just put a couple of .jar files in the right place, read the javadoc and away you go.
With python, it doesn't seem to be like that. I wanted to hook python up to MySQL. There doesn't seem to be anything to do that in the standard modules that are available on python.org. So I did a search on google and got pointed to the home page of the guy who wrote something called mysqldb, but when I went there it said the current version had moved to sourceforge. I downloaded it from sourceforge. It didn't build. Firstly because, oops, no gcc. I had forgotten I had installed the Apple developer tools on the laptop, but now I was on the desktop which had previously spent its working life as a photoshop workstation. I downloaded the latest developer tools. Fair enough, if I need a C compiler then I need a C compiler - but I've never had to bugger about with C compilers to install a simple perl or java library to do something as fundamental as talking to a database. The MySQL thingie still wouldn't build. I googled the error message (something bizarre from gcc about being asked to build i386 code and not wanting to, which I suppose is within its rights if it knows it's running on a Mac), and found somebody who said he had submitted the fixes to setup.py for OS X to the developer months ago (but they're still not in the supposedly latest version that I had just got from sourceforge). I made the fixes. It built, but still didn't actually work when I fired up python and tried to use it.
I googled some more, and found a link to another page suggesting some different fixes to get setup.py to work properly on OS X. The page wasn't there any more. I grabbed it from the google cache. Haven't tried it yet though, the whole experience so far has just been too depressing and discouraging and meanwhile I've been busy actually getting work done in java.
I know it's always frustrating getting to know a new development environment - I've learned enough over the years to know I should budget at least a full day mucking about with stupid configuration settings before I can actually get anything productive done. But the impression I'm getting so far is that python the environment is like perl the language - powerful but messy, inconsistent and a certain amount of aggravation and trial & error required. (Whereas perl the environment is like python the language - things are generally clean, elegant and it Just Works)
Meanwhile I already have a working version of the log analyser and have made a start on the weblogging tool (which isn't generating this page yet but will be in a day or so, baby permitting) using java, which is frustratingly verbose and irritatingly pedantic with its type and exception checking, but also Works.
traffic to alanlittle.org
24th July 2003 permanent link
I've been doing some analysis of the visitors to alanlittle.org, and thought the results could conceivably be of interest to somebody.
First, to establish my credentials as the owner of a small, obscure website with a statistically insignificant amount of log traffic to analyse, here's a chart of page views per month since the beginning of alanlittle.org in October 2000.
Traffic has been growing steadily - or had been up until the last couple of months, when I became a father and didn't have time to write anything any more. In total I have around 1.1 million raw hits in my logs, of which around 200,000 represent successful views of html pages by what appear to be real people using browsers. (The rest are errors, page views by robots and hits on image files - the latter are a high proportion of all hits because much of the site is a photo gallery)
What browsers are my human viewers using?
No surprises there. Netscape 4 is rapidly dying out but most of its share is being taken by Internet Explorer. Modern standards-compliant browsers like Mozilla and Safari are only increasing slowly, although Mozilla has finally overtaken Netscape 4 as the number two browser. (I do also get some hits from other minor browsers like Opera and OmniWeb, but I've excluded anything with under one percent share from the charts to avoid clutter)
I'm particularly interested in what percentage of viewers I'm getting using Macs. I bought my first mac this time last year and have been very happy with it. I've also suspected for quite a while that the subject matter of my website, primarily photography and yoga, might appeal to a disproportionately Mac-using audience.
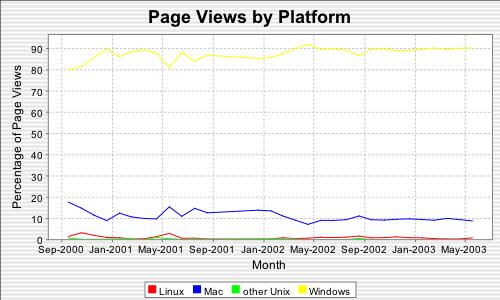
Well, my share of page views by Mac users is around 10%, which is certainly significantly higher than Apple's market share of new computer sold (2.3% in the US, the last I heard) and probably somewhat higher than their share of installed base (I'm guessing - haven't seen any reliable estimates for the Apple installed base figure). On the other hand, it's gently-but-steadily declining as Windows gently-but-steadily increases, and Linux and other Unix variants remain insignificant. (I would be interested in being able to distinguish between OS X and Mac Classic visitors, but I don't know how to do that reliably using User Agent Strings.)
The browser picture on the Mac is somewhat different.
Netscape 4 was still close to parity with Internet Explorer on the Mac two years ago, but already declining rapidly. But on the Mac, Internet Explorer market share has levelled off and a lot Netscape 4's traffic share is being taken by Mozilla and, more recently, Safari. Let's take a closer look at the bottom right hand corner of that last chart - what's been happening with non-IE browsers on the Mac since the beginning of last year.
The most striking features is Safari's rapid rise to the number 2 position with 15% share. Safari seems to have killed off Omniweb. Chimera seems to have been completely stillborn - which is a pity, I liked Chimera and used it as my standard Mac browser for a while before I switched to Safari. Hence why I chose to count it separately from other Mozilla variants - those Chimera hits are probably all me. It will be interesting to watch what happens with Safari over the next few months, particularly once it starts shipping as the standard browser on new Macs.
notes, definitions & assumptions
I'm a novice at do-it-yourself http log analysis. I used to use analog for basic statistics, but I got frustrated with it because it can't produce any cross-category reports like "browser share by platform", so decided to write my own. I have a little java programme that parses my server log files and writes them into a MySQL database where I can do ad hoc reports and analysis of whatever I happen to be interested in. Using a database would probably be unacceptably slow if I was running a millions-of-hits-an-hour site, but as we've already established, I'm not and I like the flexibility it gives me.
Here are the assumptions and definitions that the figures above are based on (some of which may be wrong):
- anything I don't otherwise recognise that reads /robots.txt is a robot
- ... and so is anything that appears in this list of robot user agent strings from pgts.com.au
- anything that isn't a robot is a browser
- only hits on html pages count. (This is actually a conservative assumption - sometimes when I'm lazy or in a hurry I link embedded thumbnail images directly to larger jpegs without wrapping them in html pages, so there could also be quite a few jpeg file views that a human being has explicitly clicked to)
- anything with an http result status in the 200s, or 304, is successful
- "Mozilla" includes Netscape 6 & 7
- "Netscape 4" includes all older Netscape versions
- I would be interested in looking at Mac Classic versus OS X, but I don't know how to reliably detect OS X using user agent strings. Some browsers only exist for OS X, and/or explicitly say "OS X" in their user agent strings, but I don't think all OS X browsers do.
- charts produced with the excellent JFreeChart (which doesn't seem to have a "powered by JFreeChart" promotional logo, otherwise I would use it)
all text and images © 2003–2008