alan little’s weblog
one simple & obvious way
18th July 2005 permanent link
One of the key qualities of python is supposed to be (and is, mostly) its cleanness and elegance. In contrast to perl, where no two programmers are ever supposed to do the same thing in the same way, in python there’s supposed to be “one simple and obvious way to do it”. Let’s look at this, for a couple of different values of “it”.
I discovered when I profiled my current project that it spends nearly half its time in a single function, and that function spends most of its time on a very common and obvious python programming scenario:
you want to look something up in a dictionary, but it might not be there
What’s the one simple and obvious way to do this? There are three. (At least).
Another python programming principle, we are often told, is it is easier to ask forgiveness than permission. So just try it, then worry about what to do if it fails:
try:
value = d[key]
except KeyError:
value = default
That should work nicely as long you’re expecting to usually find what you’re looking for. If your expected hit rate is low (it isn’t in my particular situation, but it could be), then instead of raising lots of exceptions it might be better to look before you leap:
if key in d:
value = d[key]
else:
value = default
But wait. We are also told we should use built in functions from the core python libraries wherever possible, because they are written in C code that is highly optimised and more efficient than anything we are likely to come up with ourselves. And Alex Martelli in Python in a Nutshell points out that python dictionaries have a get method that deals with precisely this situation:
value = d.get(key, default)
That saves us three lines of code (succinct is always good, right?) and should be at least as fast as the other two, if not even somehow magically faster. Er, no, as it turns out:
from time import time
lookups = 10000
hitrates = (1.00, 0.99, 0.9, 0.75, 0.5, 0.1)
for hitrate in hitrates:
d = dict([(i,i) for i in range(1, lookups * hitrate)])
start = time()
for i in lookups:
try:
value = d[i]
except KeyError:
value = 0
print 'Hit rate %f -- time for *try*: %f' % (hitrate, (time() - start))
start = time()
for i in lookups:
if i in d:
value = d[i]
else:
value = 0
print 'Hit rate %f -- time for *if*: %f' % (hitrate, (time() - start))
start = time()
for i in lookups:
value = d.get(i, 0)
print 'Hit rate %f -- time for *get*: %f' % (hitrate, (time() - start))
10,000 dictionary lookups with various hit rates. Times in milliseconds, with python 2.3 running on a 1 GHz Powerbook with OS X 10.3.9:
| Hitrate | try | if | get |
| 100% | 21 | 29 | 30 |
| 99% | 22 | 28 | 30 |
| 90% | 22 | 27 | 29 |
| 75% | 59 | 25 | 28 |
| 50% | 116 | 23 | 28 |
| 10% | 193 | 17 | 26 |
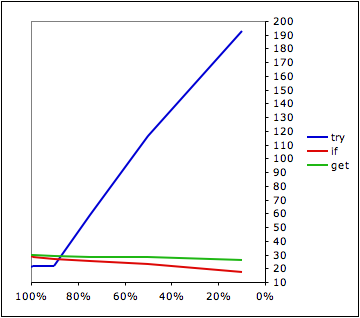
try turns out, not surprisingly, to be the fastest approach if you’re sure what you’re looking for will nearly always be there. This is probably the normal case. Once your hit rate drops off a few percent, though, the cost of raising and handling all those exceptions becomes catastrophic, and then it’s faster to look before you leap. get is always slightly slower than look before you leap. Presumably it’s doing the same thing plus some overhead for the function call. I find it hard to see what it’s there for – why clutter up the standard library with a function that saves three simple & obvious lines of code at the expense of mediocre performance?
What about another common and obvious programming scenario?
you want to develop something that has a web front end
What’s the one simple and obvious way to do this? Zope? Webware? CherryPy? Quixote? Twisted? Subway? (…)
related entries: Programming
all text and images © 2003–2008